📌 Project Overview
AI chatbot that ingests PDF documents and answers questions with contextual understanding using Retrieval Augmented Generation (RAG). Built in a single night for a client requiring fast, accurate document analysis without external API dependencies.
Uses local Llama 3.1 inference on self-managed L40 GPU infrastructure, achieving sub-2 second response times while maintaining complete data privacy and zero API costs.
📊 Performance Metrics
1.07s
Average Response Time
$10
Monthly Infrastructure Cost
100%
Data Privacy (Local Inference)
1 Night
Development Time
🛠️ Technical Stack
🏗️ Architecture
User Upload → PyPDF Parser → Text Chunking (1000 chars, 200 overlap)
↓
Sentence Embeddings (all-MiniLM-L6-v2)
↓
ChromaDB (Vector Store)
↓
Query → Semantic Search (k=3) → Context Retrieval
↓
Llama 3.1 8B (Ollama) + Prompt
↓
Answer + Source Citations
✨ Key Features
- Lightning-Fast Inference: 1.07s response time using NVIDIA L40 GPU acceleration
- RAG Architecture: Vector embeddings with semantic search for accurate context retrieval
- Multi-PDF Support: Upload and query across multiple documents simultaneously
- Source Citations: Always shows exact page/section where answers came from
- Local Inference: 100% on-premise Llama 3.1 - no OpenAI or external API needed
- Cost-Optimized: $10/month self-managed infrastructure vs $100s for API services
- Production-Ready: Deployed for real client work with Streamlit interface
🎬 Demo Screenshots

Landing Page
Clean Streamlit interface powered by Llama 3.1 on L40 GPU
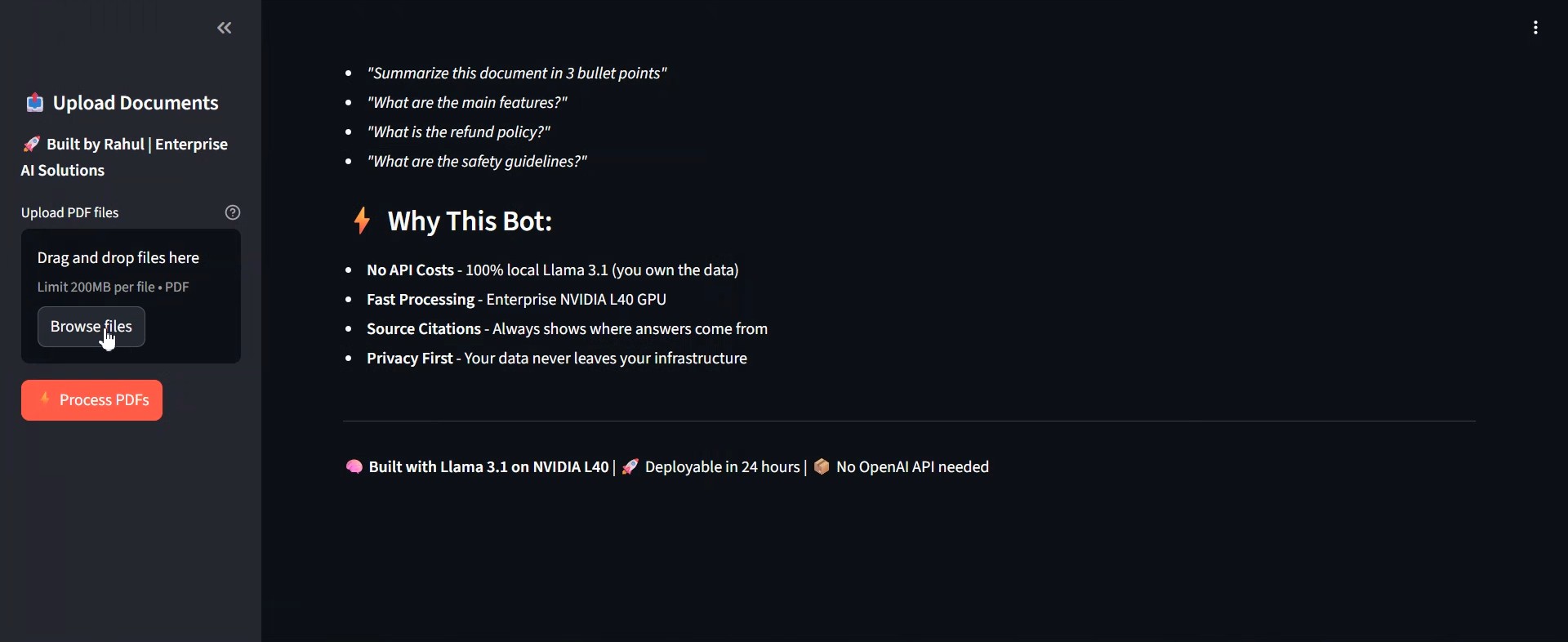
Upload Interface
Drag-and-drop PDF upload with multi-file support
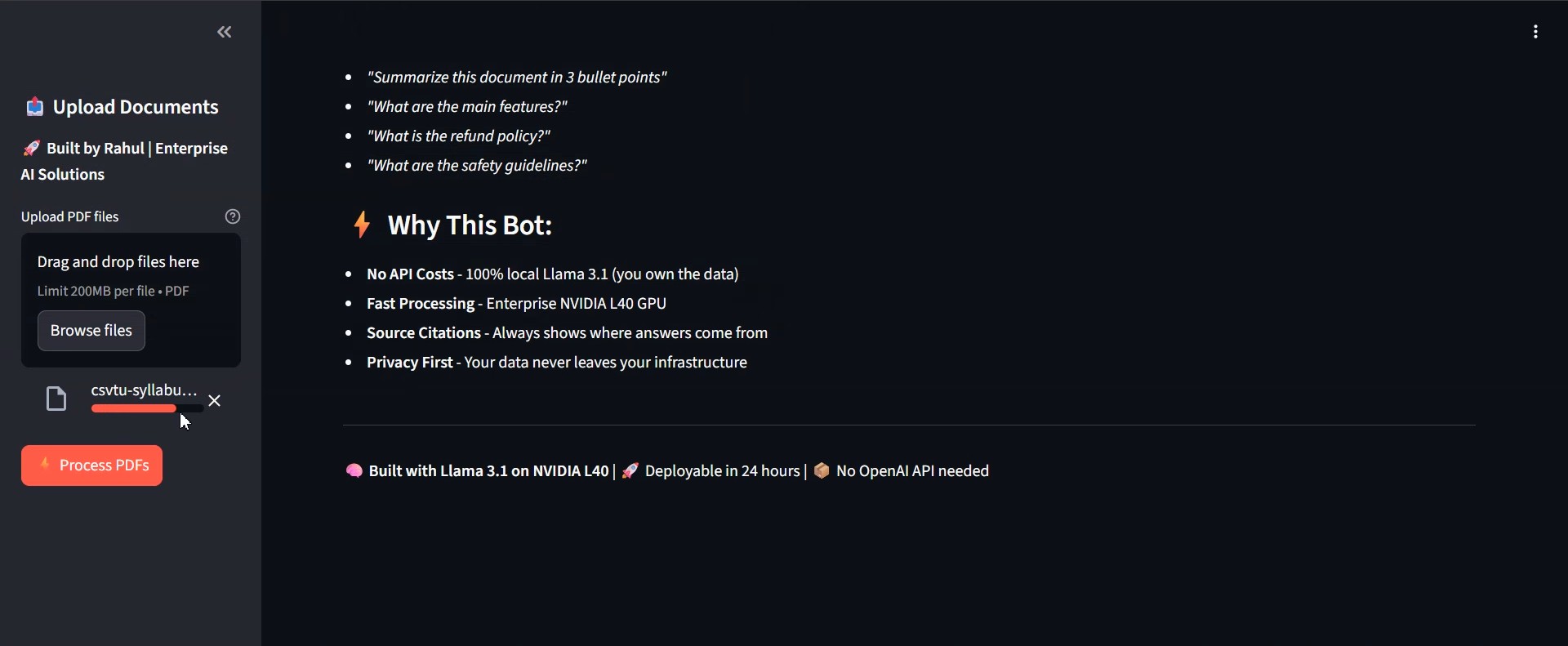
GPU Processing
L40 GPU processing with real-time status updates

Natural Language Query
Ask questions in plain English - "what is this university"
Answer with Citations
Contextual answers with expandable source citations
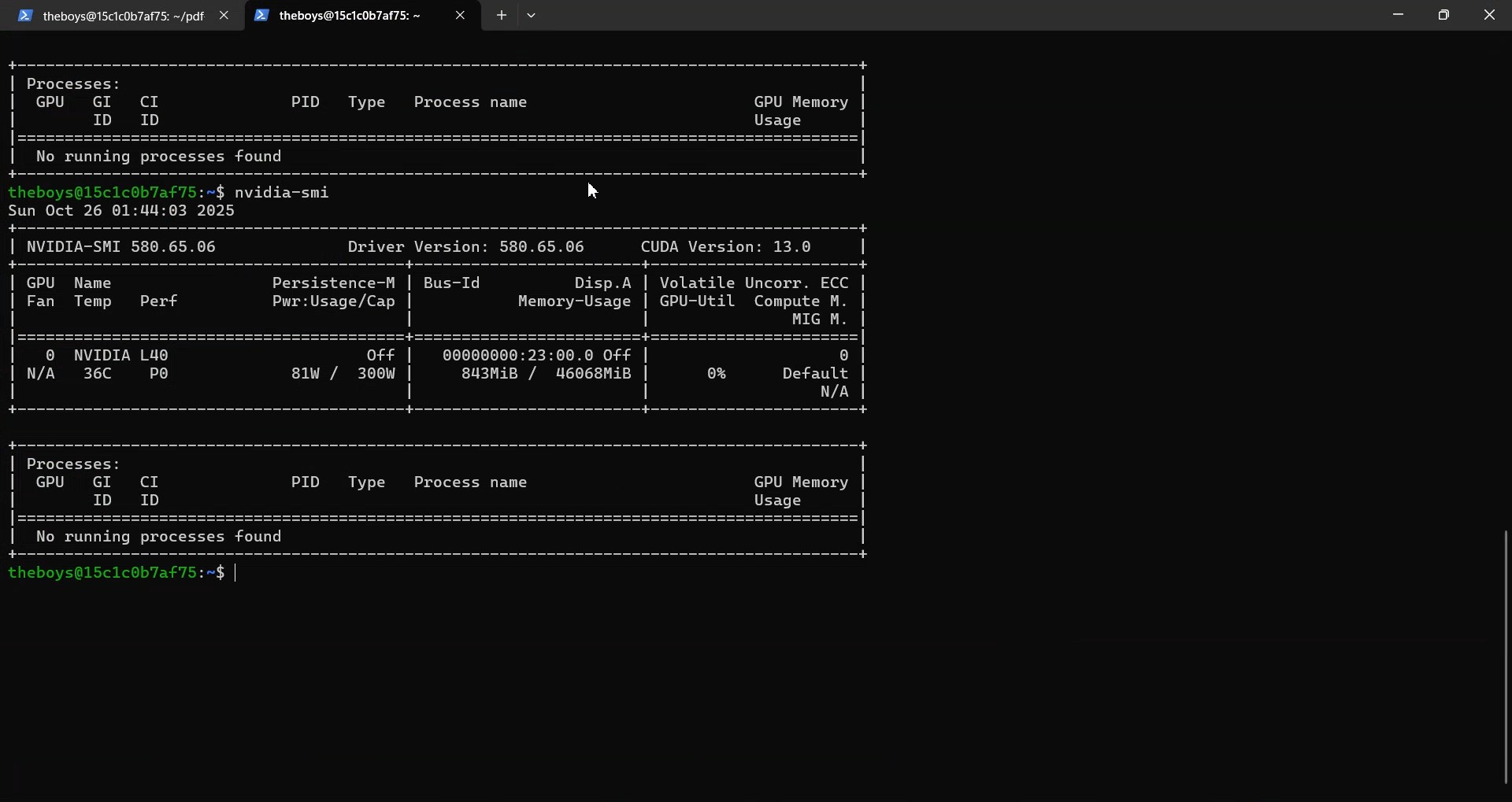
L40 GPU Infrastructure
NVIDIA L40 (46GB VRAM) - 1.07 second confirmed inference time
💡 Technical Achievements
- Rapid Development: Built complete system in single night (8 hours)
- Infrastructure Optimization: Self-managed L40 VPS at $10/month (vs $1000+/month hosted)
- Production Deployment: Successfully deployed for client with real queries
- Zero Dependencies: No external APIs - complete data sovereignty
- Efficient Chunking: 1000-char chunks with 200-char overlap for optimal retrieval
- Persistent Storage: ChromaDB with session persistence for multi-document bases
🎯 Use Cases
⚖️
Legal contract review and Q&A
📚
Research paper summaries
📖
Technical documentation search
🏢
Enterprise knowledge bases
Interested in Similar Solutions?
I build production AI systems with GPU optimization and cost-effective infrastructure.
🔗 Related Projects
🤖
DAMN
Decentralized AI Memory Network
(Built in 3 hours)
🎨
AI Image Bot
GPU-accelerated Telegram bot
(2000+ images)
🐋
Whale Tracker
Real-time blockchain monitor
(Built in 1 hour)